
If a programmer breaks their arm and has to wear a cast for two months but can’t stop working, what should they do? Erik Schluntz, a researcher at Anthropic and co-author of “Building Efficient Agents,” suggests: hand it all over to Claude.
As AI reshapes the software industry, Vibe Coding has become an essential approach for companies looking to exponentially boost productivity.
A few months ago, Schluntz shared his unique experience of being forced into “fully automated work” and discussed a somewhat controversial topic: how to responsibly implement Vibe Coding in production environments.
This insightful talk has recently gained traction on X, with users praising it as more valuable than 100 paid courses.
In the spirit of Vibe Coding, we have organized Schluntz’s talk with the help of AI.
Defining Vibe Coding
Many equate heavy use of AI tools like Cursor or Copilot to Vibe Coding. However, as long as developers maintain a close feedback loop of line-by-line modifications and reviews with the model, it cannot be considered true “vibe.”
Andre Karpathy provides a more precise definition: “Fully immersed in the vibe, embracing the exponential growth of technology, and completely forgetting the existence of code.”
This work mode significantly lowers the development barrier, allowing individuals without engineering backgrounds to independently develop complete applications. However, successful cases of this development model have historically been limited to personal games or low-risk projects. When non-professionals apply this model in real production environments, it often leads to issues like exhausting API quotas, bypassing subscription validations, or tampering with databases.
Why Embrace Exponential Growth?
Given the uncontrollable factors in high-risk business environments, why should we still push this technology? The core driving force is the exponential growth of AI capabilities.
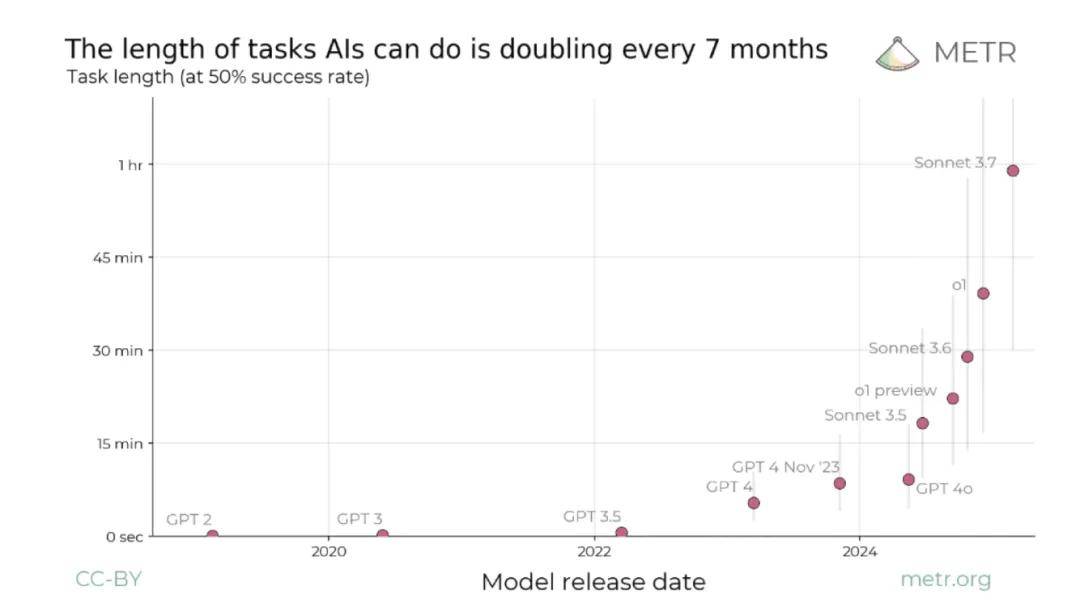
Currently, the length of tasks that AI can independently handle doubles approximately every seven months. Today, AI can reliably complete a coding task that takes an hour, and developers still have the energy to review it line by line. By next year or the year after, when AI can generate code equivalent to a human’s work for a day or even a week in one go, if we continue to insist on traditional synchronous reviews and modifications, human engineers will inevitably become a bottleneck in the face of explosive computational power.
We can look to the history of compilers for reference. Early developers may not have trusted compilers and would still check the underlying assembly code. As system scales expanded, developers had to learn to trust higher levels of abstraction. Looking ahead, the entire software engineering community must also consider how to safely and responsibly accept systems directly generated by large models in production environments.
Finding Verifiable Abstractions and the “Leaf Node” Strategy
The core idea of practicing vibe coding in production environments is: forget the existence of code, but always focus on the existence of the product.

In modern enterprise management, CTOs rely on acceptance testing to manage technical experts, product managers validate functional designs through product experience, and CEOs use key data slices to audit financial models. They do not delve into the lowest execution details. Software engineers also need to establish similar abstractions that can be verified without reading the underlying code.

The key is: find the abstraction layer you can verify!

However, there is a tricky technical obstacle in current AI coding: technical debt. Aside from reading the source code, it is challenging to measure or verify technical debt through other systematic means.
Based on this, Erik Schluntz suggests focusing on “leaf nodes” in the codebase.
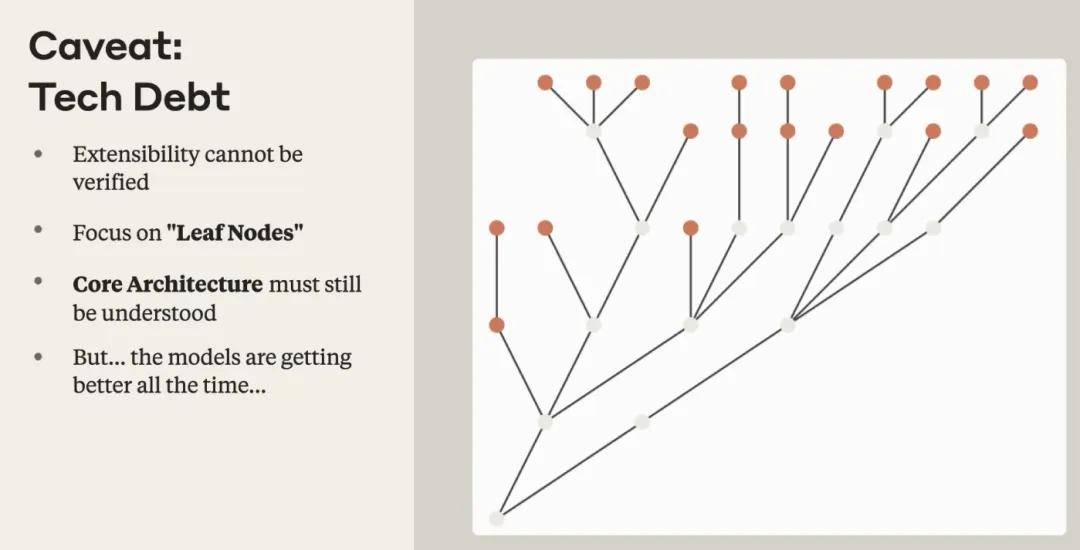
These nodes refer to end functionalities or additional components that are not dependent on any other modules. In these areas, even if some technical debt arises, it is acceptable because they change infrequently and do not hinder the construction of subsequent modules. In contrast, for the core and underlying architecture of the system, engineers still need to deeply understand and tightly protect its scalability.
Notably, as model capabilities improve, the levels of code we can trust AI to take over are extending downward. For example, in recent internal tests of a new model at Anthropic, the success rate of AI generating quality architectures is increasing, and this boundary is dynamically changing.
Being a Full-Time Product Manager for Large Models
To enable AI to output high-quality engineering code, developers need to shift their mindset and see themselves as Claude’s product managers. Instead of asking what Claude can do for you, ask what you can do for Claude.

When facing complex development tasks, developers need to guide AI like a new employee on their first day. Simply throwing out a command like “implement this feature” is destined to fail. Developers need to provide AI with detailed navigation of the codebase and clearly specify requirements and constraints.
Erik Schluntz emphasizes a standard pre-workflow he follows.
Before letting Claude actually write code, he typically spends 15 to 20 minutes interacting with it. This includes allowing AI to explore the codebase, find relevant files, and collaboratively develop a clear execution plan. Then, he compiles this comprehensive context and specifications into a single prompt and lets Claude execute it. Under this process, the model’s task success rate sees an exponential leap.
A 22,000-Line Code Merge Case in Production
In his talk, Erik Schluntz revealed an extreme practical case from within Anthropic. His team recently successfully merged a massive 22,000 lines of code changes in a reinforcement learning codebase, the vast majority of which were written by Claude.

To responsibly complete this merge, the team adopted four core strategies:
- Deep guidance from a product manager’s perspective: Spending several days on upfront manual planning and requirement sorting.
- Strictly defining the scope of changes: Limiting code changes strictly to leaf nodes where technical debt is acceptable.
- Human intervention in core areas: For core logic that must ensure underlying scalability, the team executed strict manual reviews.
- Establishing verifiable checkpoints: Designing long-term stress tests for system stability and ensuring the entire system has easily verifiable input and output standards.

Through this approach, a massive project that would have required human engineers two weeks to write and review line by line was compressed to completion within a day. When the time cost of development plummets, engineers will have the capacity to advance large-scale refactoring and feature iterations that were previously shelved due to resource constraints.
Advanced Techniques
Exploration, Testing, and Toolchain Collaboration
During a lengthy Q&A session, Erik Schluntz provided dense answers to practical details of interest to developers, covering multiple dimensions from personal growth to tool pairing.
Question 1: In the past, we spent a lot of time dealing with syntax, library files, or connections between code components, and we learned in the process. How should we learn now? How do we accumulate enough knowledge to be a good product manager for Agents?
Erik: That’s a great question. Indeed, we will no longer experience those painful struggles. But I think that’s okay, just like how today’s programmers don’t handwrite assembly code.
On the optimistic side, I’ve found that with AI tools, my speed of learning new things has greatly accelerated. Often, I ask, “Hey Claude, I’ve never seen this library, tell me about it. Why did you choose it?” Having a pair programming partner that is always online means that lazy individuals might get away with it, but as long as you’re willing to invest time to learn, Claude will help you understand it.
Additionally, with AI, we can conduct more iterations of “trial and error.” Architectural decisions that used to take two years to validate can now yield results in six months. As long as you’re willing to try, engineers can learn four times the experience in the same natural time.
Question 2: During the pre-planning process, how do you balance the amount of information you provide? Is there a standardized template?
Erik: It depends on what you care about. If I don’t care about how it’s implemented, I won’t mention any implementation details, just the final requirements. If I’m very familiar with this codebase, I will delve into specific classes to use and reference examples.
However, when you don’t impose excessive constraints on the model, it performs best. So I don’t recommend spending too much energy on strict format templates; just communicate with it like a junior engineer.
Question 3: How do you balance effectiveness and cybersecurity? For example, there have been reports that many Vibe coding applications created by those who don’t understand code have serious vulnerabilities.
Erik: It goes back to the first point: be a good PM. You need to understand the domain and know what is dangerous and what is safe. Most of the vulnerabilities reported in the media were created by people who completely don’t understand coding, so this is fine for games and toy projects. But for production systems, you need to ask the right questions to guide. Our 22,000-line code case was a completely offline task, so we were confident there were no security risks.
Question 4: With less than 0.5% of the global population understanding software, what changes need to be made to existing products to allow ordinary people to build software more easily while avoiding security issues like leaking API keys?
Erik: It would be great if more products and frameworks could emerge that achieve “provably correct” levels of accuracy. For example, if someone could build a system that locks down important authentication and payment parts on the backend while leaving a “fill-in-the-blank” frontend sandbox for you to vibe code.
A simple example is Claude Artifacts, which is hosted in the cloud, has only a frontend, and no permissions or payments, so you can mess around safely. I hope someone develops good tools that can serve as supplements.
Question 5: Do you have any tips on test-driven development (TDD)? Claude often gets stuck in tests.
Erik: TDD is extremely useful in Vibe Coding. Even if you don’t understand the test cases, it can help Claude become more coherent.
However, Claude tends to write “dead-end tests” that overly depend on specific implementations. My approach is to enforce standards: “Only write 3 end-to-end (E2E) tests: one for the happy path, error scenario 1, and error scenario 2.” Guide it to write extremely minimal end-to-end tests, ensuring that even I can understand them.
When vibe coding, the only code I usually look at is the test code. If the tests pass, I feel confident.
Question 6: Andre Karpathy said, “Embrace exponential growth.” What does that mean? Will models improve in every dimension we expect?
Erik: The core of exponential growth is not just continuous improvement, but the speed at which they improve far exceeds our imagination. It’s like a scatter plot; it starts with a gentle rise and then suddenly skyrockets.
Looking back at the computer enthusiasts of the 90s, from a few KB of memory to today’s TB-level storage, that’s not just a twofold improvement, but millions of times better. So we shouldn’t think about “what will happen if the model is twice as good in 20 years,” but rather “what if it is a million times smarter than today?” This is incredibly crazy; this is what it means to embrace “exponential.”
Question 7: You have two workflows, one in the terminal (Claude Code) and one in VS Code/Cursor. Which do you usually use? How often do you compact the context? It tends to go off track over time.
Erik: I use both. Most modifications are done in Claude Code, while I review the code (or tests) in VS Code.
I usually compact when I feel there’s a pause point where a “human programmer would stop for lunch.” My starting point is usually: first, let Claude find all relevant files and create a plan, then have it write all of that into a document, and I immediately compact. This way, I can discard the 100,000 tokens spent on planning and compress it down to just a few thousand clean tokens.
Question 8: Do you use multiple Claude Code sessions simultaneously and then merge results? How do you approach PR in an engineering manner instead of writing randomly when dealing with unfamiliar codebases?
Erik: Yes, I use Claude Code to set up the framework and then use Cursor to finish and fix it. For specific lines I know need changing, I directly modify them using Cursor.
When facing an unfamiliar codebase, before writing functionality, I first use Claude Code to help me explore. I ask, “Where is the code handling Auth?” “What functionalities are similar to this?” “List the classes I should review.” This helps me build a global view in my mind, ensuring I can manage what’s happening smoothly before diving in with Claude.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.