Introduction
Anthropic’s latest model, Claude Opus 4.7, has officially launched. Compared to Opus 4.6, Opus 4.7 shows marked improvements in advanced software engineering tasks, particularly in handling complex challenges. Anthropic claims it processes long tasks more reliably, executes instructions more precisely, and performs validation before returning results.
Key Features of Opus 4.7
Previously, Anthropic released Project Glasswing, discussing the risks and value of AI models in cybersecurity. They indicated that Claude Mythos Preview would limit its release scope while prioritizing testing new security mechanisms on less capable models.
Opus 4.7 is the first model to take on this role, with its cybersecurity capabilities not matching those of Mythos Preview. For professionals with legitimate cybersecurity needs, such as vulnerability research and penetration testing, Anthropic has launched the Cyber Verification Program for applications.
The pricing for Opus 4.7 remains the same as Opus 4.6: $5 per million tokens for input and $25 per million tokens for output. Developers can access the model via the Claude API using the name claude-opus-4-7.
Improvements in Instruction Following
Opus 4.7 shows significant enhancements in instruction adherence. This leads to a change: prompts written for older models may yield inconsistent results, as those models might misinterpret or overlook certain instructions. In contrast, Opus 4.7 executes instructions more strictly and literally, necessitating users to adjust their prompts accordingly.
Enhanced Multimodal Capabilities
Opus 4.7’s visual capabilities have significantly improved, allowing it to process images with a maximum long edge of 2576 pixels (approximately 3.75 million pixels), more than three times that of previous Claude models. This enhancement enables applications that rely on detailed visual information, such as reading complex screenshots and extracting data from intricate charts.
Business Performance
In practical applications, Opus 4.7 has achieved the best performance in Finance Agent evaluations and outperforms Opus 4.6 in financial analysis tasks. It generates more rigorous analytical models and professional presentation content while enabling tighter collaboration across multiple tasks.
Memory Capabilities
Opus 4.7 utilizes a file system-based memory mechanism more effectively, allowing it to retain key information across long-term tasks and reduce the burden of contextual input in subsequent tasks.
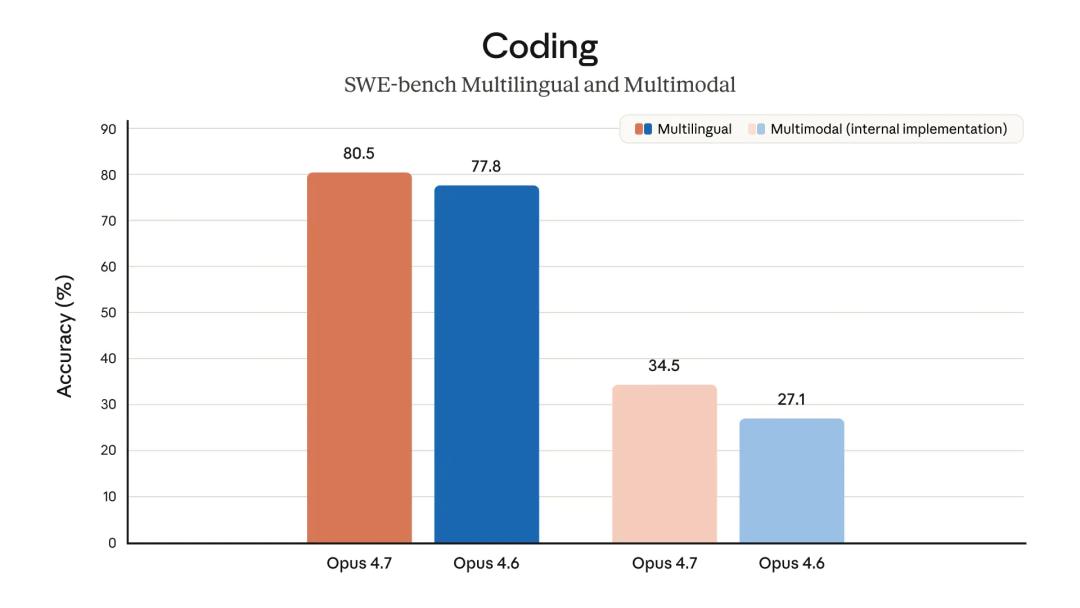
Additional Updates
Several updates accompany the model release:
-
Granular Control of Reasoning Intensity: Opus 4.7 introduces an
xhighreasoning level betweenhighandmax, allowing users to flexibly balance reasoning depth and latency for complex issues. The default reasoning intensity in Claude Code has been raised toxhigh, with recommendations to start testing fromhighorxhighfor coding and agent scenarios. -
Claude Platform Enhancements: In addition to supporting higher resolution images, task budgets have been introduced (currently in public beta) to manage token consumption and allocate resources more effectively during long tasks.
-
New Command in Claude Code: The
/ultrareviewcommand initiates dedicated code review sessions, automatically reading changes and identifying potential bugs and design issues, approaching the review capability of a seasoned engineer. Pro and Max users receive three free experiences of this feature. Additionally, the auto mode has been extended to Max users, allowing Claude to make some decisions on behalf of the user, reducing interruptions during long tasks while maintaining lower risks than completely bypassing permission controls. -
Token Usage Changes: Transitioning from Opus 4.6 to 4.7 involves two notable changes regarding token usage. First, Opus 4.7 employs a new tokenizer, improving text processing efficiency but potentially mapping the same input to more tokens (approximately 1.0 to 1.35 times more, depending on content type). Second, at higher reasoning intensities, particularly during the later stages of multi-turn agent tasks, the model performs more reasoning, resulting in more output tokens. This enhances the reliability of complex tasks but also increases token consumption.
Users can manage token usage by adjusting the effort parameter, setting task budgets, or requesting more concise outputs in prompts. Internal testing shows overall positive results: in an internal coding evaluation, token usage efficiency improved across all reasoning intensity levels. However, real-world traffic measurement is still recommended. Anthropic also provides migration guides to assist users in smoothly upgrading from Opus 4.6 to Opus 4.7.
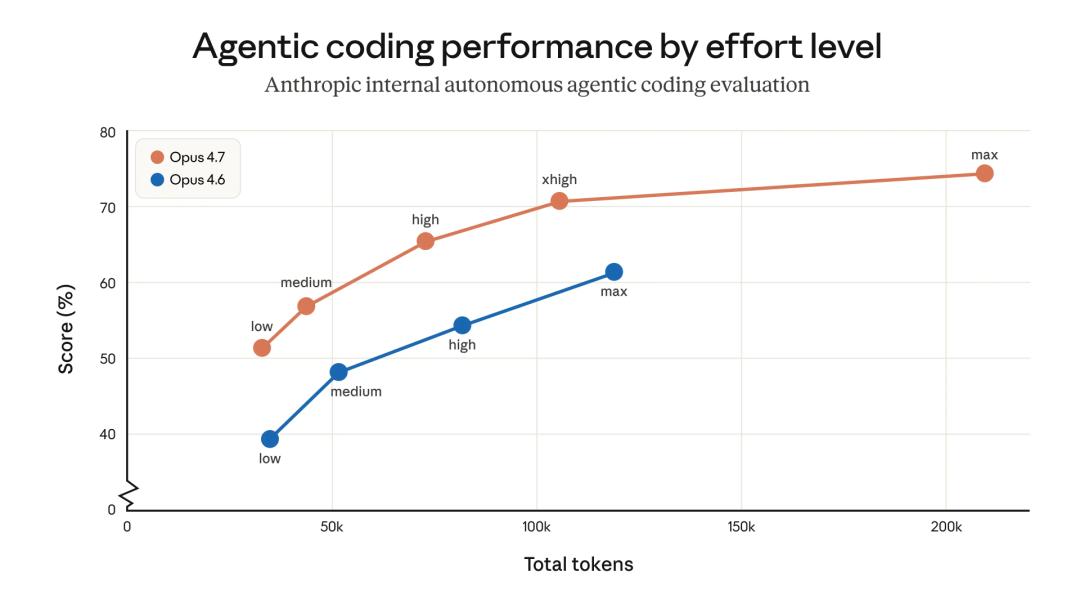
Insights from Claude Code’s Creator
Boris Cherny, the creator of Claude Code, shared practical insights after several weeks of internal use of Opus 4.7. His overall impression is clear: productivity has significantly increased, but adjustments in usage are necessary.
Key Takeaways:
-
Auto Mode: Opus 4.7 excels at handling complex, long-running tasks such as deep research, code refactoring, and iterative performance development. Previously, users had to monitor the model closely or use risky methods like
--dangerously-skip-permissions. The new auto mode offers a safer alternative, where permission requests are evaluated by a model-based classifier to determine safe execution. -
Fewer Permission Prompts: The new skill
/fewer-permission-promptsscans the session history to identify safe bash or MCP commands that repeatedly trigger permission prompts, recommending their addition to an allowlist. This function helps streamline permission policies and reduce unnecessary interruptions. -
Recaps: This simple yet practical feature generates a brief summary for each agent, explaining what was just done and what comes next. This is particularly useful for long-running tasks, allowing users to quickly regain context after returning to the task.
-
Focus Mode: The newly added focus mode in the CLI hides all intermediate processes, displaying only the final results. Boris notes that the model has evolved to a stage where it can generally be trusted to execute commands correctly, so users only need to see the final outcome.
-
Effort Adjustment: Opus 4.7 no longer relies on a fixed thinking budget but instead employs an adaptive thinking mechanism. Users can control how much the model
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.